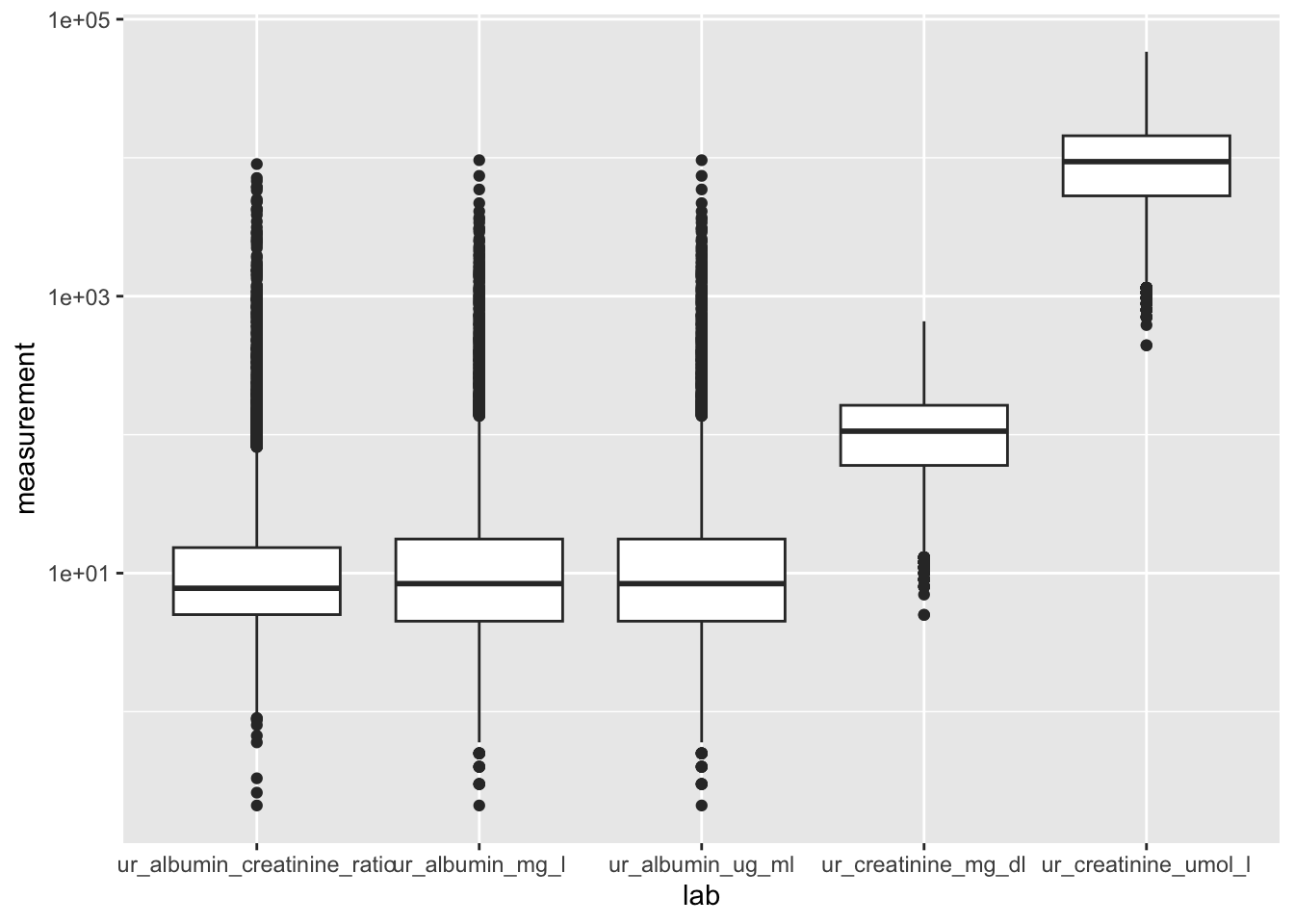
This data is in a long format–there are multiple rows for each observational unit, each corresponding to a different variable being measured (in this case, the different labs).
A wide format, on the other hand, will only have one row for each observational unit (respondent), and each of the individual variables being measured (the labs) will have their own column, each containing the values for the corresponding lab.
You can convert from a long format to a wide format using the pivor_wider() function.
The code below creates a wide-form version of the labs data, and saves it as a new data frame called labs_data_wide:
# use pivot_wider() to convert the labs data from a # long format to a wide format. # arguments are `names_from` and `values_from`# save the wide data as `labs_data_wide`.labs_data_wide <- labs_data |>pivot_wider(names_from ="lab", values_from ="measurement")labs_data_wide
If you want to convert from a wide format dataset into a longer-format dataset, you can instead use the pivot_longer() function.
# use pivot_longer() to convert labs_data_wide back to along format# arguments are `cols` (use a select helper!), `names_to` and `values_to`labs_data_wide |>pivot_longer(cols =starts_with("ur_"), names_to ="lab",values_to ="measurement")
Use-case for long-format: creating a visualization that compares the different variables using ggplot2.
# create boxplots using the long format for the measurements from each lab# maybe add a log-scale to the y-axislabs_data |>ggplot() +geom_boxplot(aes(x = lab, y = measurement)) +scale_y_log10()
Warning: Removed 1195 rows containing non-finite outside the scale range
(`stat_boxplot()`).
Exercise
Load the demographics data and use select() to select just the respondent_id, gender, marital_status and race columns and then use pivot_longer() to create the following long-format table (below are just the first 10 rows).
respondent_id name value
1 73557 gender male
2 73557 marital_status separated 3 73557 race black
4 73558 gender male
5 73558 marital_status married
6 73558 race white
7 73559 gender male
8 73559 marital_status married
9 73559 race white
10 73560 gender male
Solution
demographics <-read_csv("data/demographics.csv")
Rows: 10175 Columns: 19
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): interview_examination, gender, race, marital_status, pregnant
dbl (9): respondent_id, age_years, age_months_sc_0_2yr, six_month_period, ag...
lgl (5): served_active_duty_us, served_active_duty_foreign, born_usa, citize...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
demographics
# A tibble: 10,175 × 19
respondent_id interview_examination gender age_years age_months_sc_0_2yr
<dbl> <chr> <chr> <dbl> <dbl>
1 73557 both interview and exam male 69 NA
2 73558 both interview and exam male 54 NA
3 73559 both interview and exam male 72 NA
4 73560 both interview and exam male 9 NA
5 73561 both interview and exam female 73 NA
6 73562 both interview and exam male 56 NA
7 73563 both interview and exam male 0 5
8 73564 both interview and exam female 61 NA
9 73565 interview only male 42 NA
10 73566 both interview and exam female 56 NA
# ℹ 10,165 more rows
# ℹ 14 more variables: race <chr>, six_month_period <dbl>,
# age_months_ex_0_19yr <dbl>, served_active_duty_us <lgl>,
# served_active_duty_foreign <lgl>, born_usa <lgl>, citizen_usa <lgl>,
# time_in_us <dbl>, education_youth <dbl>, education <dbl>,
# marital_status <chr>, pregnant <chr>, language_english <lgl>,
# household_income <dbl>
# A tibble: 30,525 × 3
respondent_id name value
<dbl> <chr> <chr>
1 73557 gender male
2 73557 marital_status separated
3 73557 race black
4 73558 gender male
5 73558 marital_status married
6 73558 race white
7 73559 gender male
8 73559 marital_status married
9 73559 race white
10 73560 gender male
# ℹ 30,515 more rows