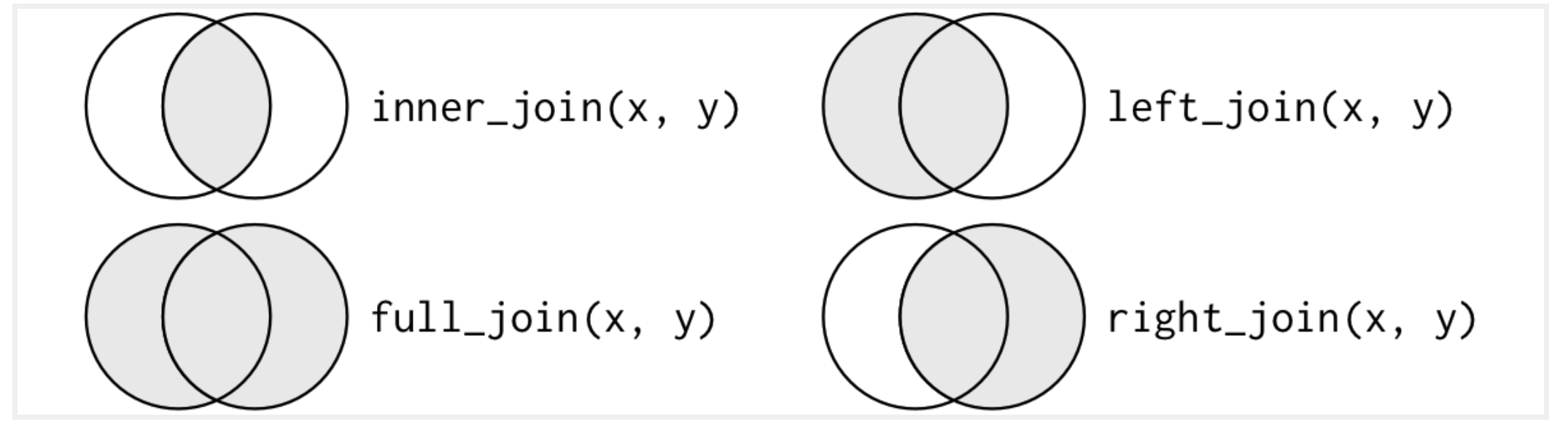At the end of this lesson we will have created a single data frame that contains the information from both the demographics data and the urine albumin and creatinine labs data.
# load the tidyverse, the demographics, and the urine_albumin_creatinine datalibrary(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
demographics <-read_csv("data/demographics.csv")
Rows: 10175 Columns: 19
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): interview_examination, gender, race, marital_status, pregnant
dbl (9): respondent_id, age_years, age_months_sc_0_2yr, six_month_period, ag...
lgl (5): served_active_duty_us, served_active_duty_foreign, born_usa, citize...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 41455 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): lab
dbl (2): respondent_id, measurement
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Determining what kind of join to do
There are four kinds of joins that you might want to use for combining two tables into a single table:
Diagram of joins
An inner join, which will keep only the data for the observational units that appear in both tables
A left join, which will keep all of the data for the observational units in the first (left) table, and will add missing values when there is no available data in the second table.
A right join, which will keep all of the data for the observational units in the second (right) table, and will add missing values when there is no available data in the first table.
A full join, which will keep all of the data for the observational units in both the first (left) table, and will add missing values when there is no available data in the other table.
The kind of join that you will implement will depend on what you want to use your joined data for.
Checking the uniqueness of the key ID variables
Below, we see that the respondent_id column is indeed unique for demographics:
# check whether the respondent ID values in demographics are unique?identical(unique(demographics$respondent_id), demographics$respondent_id)
[1] TRUE
But not for labs:
# check whether the respondent ID values in labs are unique?identical(unique(labs$respondent_id), labs$respondent_id)
[1] FALSE
Checking overlap between tables
Are there any observations in the demographics table that do not appear in the labs table?
# Compute the proportion of people in demographics who are also in labssum(unique(demographics$respondent_id) %in%unique(labs$respondent_id)) /n_distinct(demographics$respondent_id)
[1] 0.8148403
The calculation above shows that around 81% of observations in the demographics table have available labs data.
Are there any observations in the labs table that do not appear in the demographics table?
# proportion of people in labs who are also in demographicssum(unique(labs$respondent_id) %in%unique(demographics$respondent_id)) /n_distinct(labs$respondent_id)
[1] 1
The calculation above shows that 100% of observations in the labs table have available demographics data.
Joining demographics and labs
Our two options for to join demographics (left) and labs (right) are:
An inner or right join will only keep the 81% of people in demographics who have available labs data
A left or full join will keep all people in demographics data, and join missing values for those who don’t have labs data available
Since we don’t want to discard any data, we will choose the left/full join.
# perform a left/full join of demographics and labsprint(left_join(demographics, labs, by ="respondent_id"), width =Inf)
# A tibble: 43,339 × 21
respondent_id interview_examination gender age_years age_months_sc_0_2yr
<dbl> <chr> <chr> <dbl> <dbl>
1 73557 both interview and exam male 69 NA
2 73557 both interview and exam male 69 NA
3 73557 both interview and exam male 69 NA
4 73557 both interview and exam male 69 NA
5 73557 both interview and exam male 69 NA
6 73558 both interview and exam male 54 NA
7 73558 both interview and exam male 54 NA
8 73558 both interview and exam male 54 NA
9 73558 both interview and exam male 54 NA
10 73558 both interview and exam male 54 NA
race six_month_period age_months_ex_0_19yr served_active_duty_us
<chr> <dbl> <dbl> <lgl>
1 black 1 NA TRUE
2 black 1 NA TRUE
3 black 1 NA TRUE
4 black 1 NA TRUE
5 black 1 NA TRUE
6 white 1 NA FALSE
7 white 1 NA FALSE
8 white 1 NA FALSE
9 white 1 NA FALSE
10 white 1 NA FALSE
served_active_duty_foreign born_usa citizen_usa time_in_us education_youth
<lgl> <lgl> <lgl> <dbl> <dbl>
1 TRUE TRUE TRUE NA NA
2 TRUE TRUE TRUE NA NA
3 TRUE TRUE TRUE NA NA
4 TRUE TRUE TRUE NA NA
5 TRUE TRUE TRUE NA NA
6 NA TRUE TRUE NA NA
7 NA TRUE TRUE NA NA
8 NA TRUE TRUE NA NA
9 NA TRUE TRUE NA NA
10 NA TRUE TRUE NA NA
education marital_status pregnant language_english household_income
<dbl> <chr> <chr> <lgl> <dbl>
1 3 separated <NA> TRUE 17500
2 3 separated <NA> TRUE 17500
3 3 separated <NA> TRUE 17500
4 3 separated <NA> TRUE 17500
5 3 separated <NA> TRUE 17500
6 3 married <NA> TRUE 40000
7 3 married <NA> TRUE 40000
8 3 married <NA> TRUE 40000
9 3 married <NA> TRUE 40000
10 3 married <NA> TRUE 40000
lab measurement
<chr> <dbl>
1 ur_albumin_ug_ml 4.3
2 ur_albumin_mg_l 4.3
3 ur_creatinine_mg_dl 39
4 ur_creatinine_umol_l 3448.
5 ur_albumin_creatinine_ratio 11.0
6 ur_albumin_ug_ml 153
7 ur_albumin_mg_l 153
8 ur_creatinine_mg_dl 50
9 ur_creatinine_umol_l 4420
10 ur_albumin_creatinine_ratio 306
# ℹ 43,329 more rows
print(full_join(demographics, labs, by ="respondent_id"), width =Inf)
# A tibble: 43,339 × 21
respondent_id interview_examination gender age_years age_months_sc_0_2yr
<dbl> <chr> <chr> <dbl> <dbl>
1 73557 both interview and exam male 69 NA
2 73557 both interview and exam male 69 NA
3 73557 both interview and exam male 69 NA
4 73557 both interview and exam male 69 NA
5 73557 both interview and exam male 69 NA
6 73558 both interview and exam male 54 NA
7 73558 both interview and exam male 54 NA
8 73558 both interview and exam male 54 NA
9 73558 both interview and exam male 54 NA
10 73558 both interview and exam male 54 NA
race six_month_period age_months_ex_0_19yr served_active_duty_us
<chr> <dbl> <dbl> <lgl>
1 black 1 NA TRUE
2 black 1 NA TRUE
3 black 1 NA TRUE
4 black 1 NA TRUE
5 black 1 NA TRUE
6 white 1 NA FALSE
7 white 1 NA FALSE
8 white 1 NA FALSE
9 white 1 NA FALSE
10 white 1 NA FALSE
served_active_duty_foreign born_usa citizen_usa time_in_us education_youth
<lgl> <lgl> <lgl> <dbl> <dbl>
1 TRUE TRUE TRUE NA NA
2 TRUE TRUE TRUE NA NA
3 TRUE TRUE TRUE NA NA
4 TRUE TRUE TRUE NA NA
5 TRUE TRUE TRUE NA NA
6 NA TRUE TRUE NA NA
7 NA TRUE TRUE NA NA
8 NA TRUE TRUE NA NA
9 NA TRUE TRUE NA NA
10 NA TRUE TRUE NA NA
education marital_status pregnant language_english household_income
<dbl> <chr> <chr> <lgl> <dbl>
1 3 separated <NA> TRUE 17500
2 3 separated <NA> TRUE 17500
3 3 separated <NA> TRUE 17500
4 3 separated <NA> TRUE 17500
5 3 separated <NA> TRUE 17500
6 3 married <NA> TRUE 40000
7 3 married <NA> TRUE 40000
8 3 married <NA> TRUE 40000
9 3 married <NA> TRUE 40000
10 3 married <NA> TRUE 40000
lab measurement
<chr> <dbl>
1 ur_albumin_ug_ml 4.3
2 ur_albumin_mg_l 4.3
3 ur_creatinine_mg_dl 39
4 ur_creatinine_umol_l 3448.
5 ur_albumin_creatinine_ratio 11.0
6 ur_albumin_ug_ml 153
7 ur_albumin_mg_l 153
8 ur_creatinine_mg_dl 50
9 ur_creatinine_umol_l 4420
10 ur_albumin_creatinine_ratio 306
# ℹ 43,329 more rows
Look at the results above, does something look wrong to you?
If your key ID variable has repeated values, your joined data will too.
A good check after completing a join is to make sure that the number of rows in the resulting joined data matches what you expect
# check the number of rows in the joined datanrow(left_join(demographics, labs, by ="respondent_id"))
[1] 43339
# check the number of rows in demographicsnrow(demographics)
[1] 10175
Therefore, to ensure that we have just one row per observational unit (i.e., per respondent_id value), we need to join the wide-format labs_wide data instead of the long-format labs data.
# compute the wide format of the labs datalabs_wide <- labs |>pivot_wider(names_from ="lab", values_from ="measurement")labs_wide
# join demographics and labs_wideprint(left_join(demographics, labs_wide, by ="respondent_id"), width =Inf)
# A tibble: 10,175 × 24
respondent_id interview_examination gender age_years age_months_sc_0_2yr
<dbl> <chr> <chr> <dbl> <dbl>
1 73557 both interview and exam male 69 NA
2 73558 both interview and exam male 54 NA
3 73559 both interview and exam male 72 NA
4 73560 both interview and exam male 9 NA
5 73561 both interview and exam female 73 NA
6 73562 both interview and exam male 56 NA
7 73563 both interview and exam male 0 5
8 73564 both interview and exam female 61 NA
9 73565 interview only male 42 NA
10 73566 both interview and exam female 56 NA
race six_month_period age_months_ex_0_19yr served_active_duty_us
<chr> <dbl> <dbl> <lgl>
1 black 1 NA TRUE
2 white 1 NA FALSE
3 white 2 NA TRUE
4 white 1 119 NA
5 white 1 NA FALSE
6 mexican american 1 NA TRUE
7 white 2 6 NA
8 white 2 NA FALSE
9 other hispanic NA NA FALSE
10 white 1 NA FALSE
served_active_duty_foreign born_usa citizen_usa time_in_us education_youth
<lgl> <lgl> <lgl> <dbl> <dbl>
1 TRUE TRUE TRUE NA NA
2 NA TRUE TRUE NA NA
3 TRUE TRUE TRUE NA NA
4 NA TRUE TRUE NA 3
5 NA TRUE TRUE NA NA
6 FALSE TRUE TRUE NA NA
7 NA TRUE TRUE NA NA
8 NA TRUE TRUE NA NA
9 NA TRUE TRUE NA NA
10 NA TRUE TRUE NA NA
education marital_status pregnant language_english household_income
<dbl> <chr> <chr> <lgl> <dbl>
1 3 separated <NA> TRUE 17500
2 3 married <NA> TRUE 40000
3 4 married <NA> TRUE 70000
4 NA <NA> <NA> TRUE 60000
5 5 married <NA> TRUE 100000
6 4 divorced <NA> TRUE 60000
7 NA <NA> <NA> TRUE 100000
8 5 widowed <NA> TRUE 70000
9 3 married <NA> TRUE 100000
10 3 divorced <NA> TRUE 17500
ur_albumin_ug_ml ur_albumin_mg_l ur_creatinine_mg_dl ur_creatinine_umol_l
<dbl> <dbl> <dbl> <dbl>
1 4.3 4.3 39 3448.
2 153 153 50 4420
3 11.9 11.9 113 9989.
4 16 16 76 6718.
5 255 255 147 12995.
6 123 123 74 6542.
7 NA NA NA NA
8 19 19 242 21393.
9 NA NA NA NA
10 1.3 1.3 18 1591.
ur_albumin_creatinine_ratio
<dbl>
1 11.0
2 306
3 10.5
4 21.0
5 173.
6 166.
7 NA
8 7.85
9 NA
10 7.22
# ℹ 10,165 more rows
Exercise
How many rows would you expect an inner join of demographics and labs_wide to have? Check your answer by conducting the join using inner_join()
Solution
The number of rows should match the intersection of the two datasets. Since all people in labs_wide are also in demographics (but not the other way around), the join will have the same number of rows in labs_wide.
nrow(labs_wide)
[1] 8291
The join can be conducted using inner_join() and notice that the number of rows matches labs_wide.
inner_join(demographics, labs_wide, by ="respondent_id")
# A tibble: 8,291 × 24
respondent_id interview_examination gender age_years age_months_sc_0_2yr
<dbl> <chr> <chr> <dbl> <dbl>
1 73557 both interview and exam male 69 NA
2 73558 both interview and exam male 54 NA
3 73559 both interview and exam male 72 NA
4 73560 both interview and exam male 9 NA
5 73561 both interview and exam female 73 NA
6 73562 both interview and exam male 56 NA
7 73564 both interview and exam female 61 NA
8 73566 both interview and exam female 56 NA
9 73567 both interview and exam male 65 NA
10 73568 both interview and exam female 26 NA
# ℹ 8,281 more rows
# ℹ 19 more variables: race <chr>, six_month_period <dbl>,
# age_months_ex_0_19yr <dbl>, served_active_duty_us <lgl>,
# served_active_duty_foreign <lgl>, born_usa <lgl>, citizen_usa <lgl>,
# time_in_us <dbl>, education_youth <dbl>, education <dbl>,
# marital_status <chr>, pregnant <chr>, language_english <lgl>,
# household_income <dbl>, ur_albumin_ug_ml <dbl>, ur_albumin_mg_l <dbl>, …
Note that if there were observations in labs_wide that were not in demographics, then the resulting inner join will have fewer rows than both tables.